PEGASUS
Official
Summary
They propose pre-training large Transformer-based encoder-decoder models. The important sentences are removed/masked from an input document and are generated together as one output sequence from the remaining sentences (similar to extractive summary). Recent work leveraging pre-trained Transformer-based sequence-to-sequence models has extended the success in NLP tasks to text generation, including abstractive summarization.
Architecture

Pre-Training Task
Masking whole sentences from a document and generating these gap-sentences from the rest of the document works well as a pre-training objective for downstream summarization tasks. Choosing putatively important sentences outperforms lead or randomly selected ones. This self-supervised objective is called Gap Sentences Generation (GSG).
We select and mask whole sentences from documents, and concatenate the gap-sentences into a pseudo-summary. The corresponding position of each selected gap sentence is replaced by a mask token to inform the model. Gap Sentences Ratio (GSR), refers to the number of selected gap sentences to the total number of sentences in the document.
We select sentences that appear to be important to the document, based on 3 primary strategies:
- Random (uniformly select m)
- Lead (first m)
- Principal (top-m scored independently and selected sequentially according to importance computed by ROUGE-F1 but with n-grams as sets)

We apply Masked Language Model (MLM) to train the Transformer encoder as the sole pre-training objective or along with GSG. However, MLM does not improve downstream tasks at large number of pre-training steps.
We consider two large text corpora:
- C4 (Colossal and Cleaned version of Common Crawl)
- HugeNews
Downstream Tasks
We use public abstractive summarization datasets accessible through:
 https://www.tensorflow.org/datasets/catalog/overview
https://www.tensorflow.org/datasets/catalog/overview
Experiments



There are several paragraph-ideal-model examples appended to the paper.
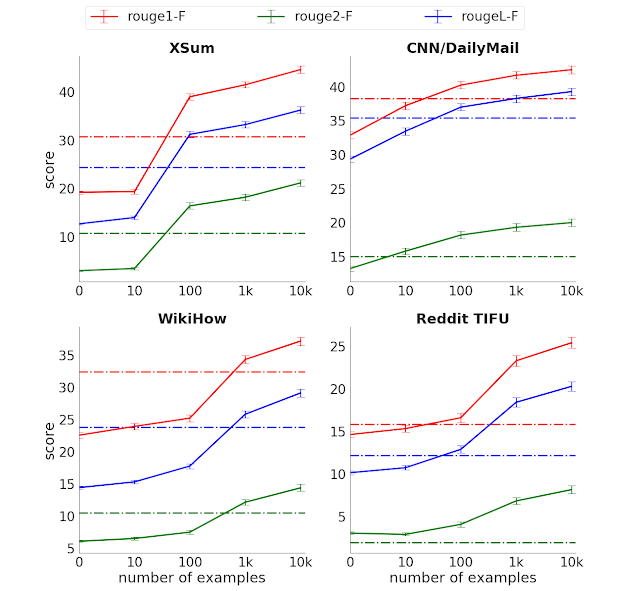
Performance





Further Readings
 https://towardsdatascience.com/how-to-perform-abstractive-summarization-with-pegasus-3dd74e48bafb
https://towardsdatascience.com/how-to-perform-abstractive-summarization-with-pegasus-3dd74e48bafb
 https://medium.com/analytics-vidhya/pegasus-pre-training-with-extracted-gap-sentences-for-abstractive-summarization-acb238aa1096
https://medium.com/analytics-vidhya/pegasus-pre-training-with-extracted-gap-sentences-for-abstractive-summarization-acb238aa1096
 https://pub.towardsai.net/summarization-using-pegasus-model-with-the-transformers-library-553cd0dc5c2
https://pub.towardsai.net/summarization-using-pegasus-model-with-the-transformers-library-553cd0dc5c2 https://towardsdatascience.com/pegasus-google-state-of-the-art-abstractive-summarization-model-627b1bbbc5ce?gi=00cf4c1329a3
https://towardsdatascience.com/pegasus-google-state-of-the-art-abstractive-summarization-model-627b1bbbc5ce?gi=00cf4c1329a3