BART
Official
Summary
BART is a denoising autoencoder for pre-training sequence-to-sequence models. BART is trained by corrupting text with an arbitrary noise function and learning a model to reconstruct the original text.
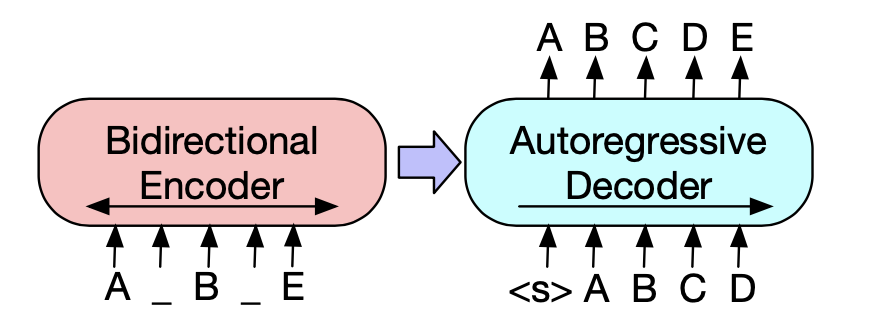
It uses a standard Transformer-based neural machine translation architecture which, despite its simplicity, can be seen as generalizing BERT (due to the bidirectional encoder), GPT (with the left-to-right decoder), and many other more recent pre-training schemes.
BART also presents a new scheme for machine translation where a BART model is stacked above a few additional transformer layers. These layers are trained to essentially translate the foreign language to noised English, by propagation through BART, thereby using BART as a pre-trained target-side language model.
Architecture

It uses standard sequence-to-sequence Transformer architecture except, following GPT, they modify ReLU activation functions to GeLUs and initialise parameters from N(0,0.02). The architecture is closely related to BERT with the following differences:
- each layer of the decoder additionally performs cross-attention over the final hidden layer of the encoder (as in the transformer sequence-to-sequence model)
- BERT uses an additional feed-forward network before word prediction while BART does not
Pre-Training Task
BART pre-trains a model combining Bidirectional and Auto-Regressive Transformers. Pre-training has two stages:
- text is corrupted with an arbitrary noising function
- sequence-to-sequence model is learned to reconstruct the original text
BART optimizes a reconstruction loss - the cross-entropy between the decoder’s output and the original document. BART allows us to apply any type of document corruption.

Experiments


Performance
We evaluate a number of noising approaches, finding the best performance by both randomly shuffling the order of the original sentences and using a novel in-filling scheme where spans of text are replaced with a single mask token.


Fine-Tuning
The representations produced can be used in several ways for downstream applications such as sequence classification, token classification, sequence generation and machine translation.




Further Readings
 https://techblog.geekyants.com/text-summarization-using-facebook-bart-large-cnn
https://techblog.geekyants.com/text-summarization-using-facebook-bart-large-cnn
 https://dair.ai/BART-Summary/
https://dair.ai/BART-Summary/
 https://medium.com/mlearning-ai/paper-summary-bart-denoising-sequence-to-sequence-pre-training-for-natural-language-generation-69e41dfbb7fe
https://medium.com/mlearning-ai/paper-summary-bart-denoising-sequence-to-sequence-pre-training-for-natural-language-generation-69e41dfbb7fe
 https://www.projectpro.io/article/transformers-bart-model-explained/553
https://www.projectpro.io/article/transformers-bart-model-explained/553
 https://sshleifer.github.io/blog_v2/jupyter/2020/03/12/bart.html
https://sshleifer.github.io/blog_v2/jupyter/2020/03/12/bart.html